Final Project Outline
Problem Statement that introduces your selected topic, identifies significant goals associated with the implementation of your applied machine learning method, demonstrates why your problem is important, and describes and analyzes the complex nature of your problem including any process oriented causes and effects. Conclude your problem statement with a stated central research question. You are welcome to articulate a central research question in broad and general terms, given the abbreviated time frame for this investigation.
In wake of the coronavirus pandemic, communication has become more essential than ever. Whether it be for keeping up with important trends in the news, or staying in touch with family members online, there is no shortage of the need for frequent and accessible communication. As the world begins to reopen, face masks are sitll an essential part of everyday wear to help protect our most vulnerable populations. However, this necessity has caused issues for the Deaf and Hard of Hearing community that rely on mouth movements and facial expressions to communicate as a distinct part of American Sign Language, going beyond just hand signs, but being limited to them just the same. Inclusivity has already seen a huge shift online and in the real world, with social media sites rolling out automated captioning software (sitll in their infant stages) and translation software such as google translate providing basic real-time spoken language to language depictions. However, this same kind of service has not been explored in depth for non-spoken languages. A tool that had the ability to provide this same kind of instant translations would go miles for increasing the accessability of communication between Deaf and hearing individuals, with the potential to even help communication between the Deaf and blind communities. With this all in mind, I am aiming at answering the question of how accurately can we predict hand signs by training ASL data on a convolutional neural network.
A description of the data that you are using as input for your applied machine learning methodology, including the source of the data, the different features (variables) and well as their data class (i.e. continuous or discrete). Be sure to include a description of your dataset size (number of rows / observations as well as number of columns / variables / features) and provide context on how the data was collected as well as the source organization, as it is relevant to your investigation.
The dataset I am using comes from Ayush Thakur on Kaggle. This dataset contains 2515 files belonging to 36 classes, consisting of images of the ASL signs for 0-9 as well as basic alphabet signs. I chose this discrete dataset as it contained a comphrehensive list of the alphabet (while others excluded hand-signs that included movement) while also including number values that have the potential to be mixed up with the letters (W and 4; 0 and O). The data was organized into files for each number/image, with each of these files containing approximately 30-80 observations of each sign being displayed at slightly different positions and angles.
Example images from the dataset, spelling out the letters ‘A’, ‘S’, and ‘L’ respectively



Provide the specification for your applied machine learning method that presented the most promise in providing a solution to your problem. Include the section from your python or R script that specifies your model architecture, layers, functional arguments and specifications for compiling and fitting. Provide a brief description of how you implemented your code in practice.
To predict ASL handsigns, I believe that a convolutional neural network will provide the most promise in providing a solution for this problem of image classification.
model = keras.Sequential()
model.add(Conv2D(16,(3,3),activation="relu",input_shape=(64, 64, 3)))
model.add(MaxPool2D(2,2))
model.add(Dropout(0.2))
model.add(Conv2D(32,(3,3),activation="relu"))
model.add(MaxPool2D(2,2))
model.add(Dropout(0.25))
model.add(Conv2D(64,(3,3),activation="relu"))
model.add(MaxPool2D(2,2))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128,activation="relu"))
model.add(Dropout(0.2))
model.add(Dense(64,activation="softmax"))
model.compile(optimizer="Adam", loss="categorical_crossentropy", metrics=["accuracy"])
This model begins as a sequential model from keras, utilizing flatten and dense layers, as well as relu and softmax activation layers. The flatten and dense layers are responsible for identifying the class of an image and reducing it into one dimension. As each image can only correclty predict for one hand sign, softmax allows the model to sift through possible matches and assign it a probability of one, and the others to zero. For a similar reason-there being 36 possible predicted classes- the categorical crossentropy function allows us to track loss for multiple potential values.
Conclude with a section that preliminarily assesses model performance. Pprovide a cursory literature review that includes 2 sources that present and describes their validation. With more time and project support, estimate what an ideal outcome looks like in terms of model validation.
With the way my model is currently set up, I believe it will predict with an accuracy around 80%, with the hopes of improving this score closer to 90% with further research and modifications. Current research like the one conducted by Grant, Henson, and Sood sought to build a system to correctly classify American Sign Language signs based on hand gestures by training a convolutional neural network to recognize signs. They also used a dynamic sign language dataset in the form of x,y,z coordinates to gain insight on relative motion data when completing their classifications. This research also took into account the use of single vs two-handed signs when creating these models. A picutre of their model architecture can be seen below:
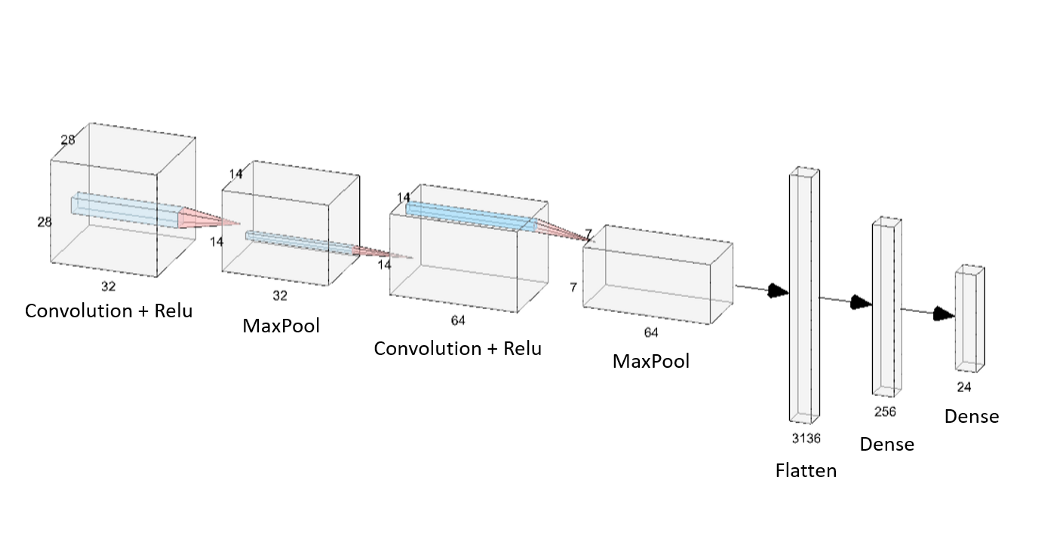
After this process, their models performed at an accuracy of 94.33% for still images, 88.9% for one-handed signs, and 79% for two-handed signs.
Alternatively, another ASL classification study by students at Johns Hopkins University used an “ASL MNIST” dataset in attempt to improve the current art of classification models by utilizing augmentation techniques, refining CNN architecture, and ensembling with predictive natural language processing. This research group also created a hand extraction method to detect the presence of skin in an image, before determining whether this feature was a hand, before finally determining its gesture. Overall, their residual neural network was able to achieve a generalized testing accuracy of 98.15%.
While still not perfect and facing many limitations, these studies into ASL-handsign classification shows how far research has come striving for better accessibility and inclusivity for Deaf and hard of hearing individuals in the future.
References
Chew, A., Mahmood, A., Silver, Z., Tamhane, A., & Huang, W.-L. (n.d.). ASL Hand Sign Classification and Prediction. Dias, R. (2019, December 18). American Sign Language Hand Gesture Recognition. Medium. https://towardsdatascience.com/american-sign-language-hand-gesture-recognition-f1c4468fb177. Thakur, Ayush. ASL Sign Language Dataset. https://www.kaggle.com/ayuraj/asl-dataset