Background
For this project, I continued on with my exploration of data from Egypt. However, due to its large population and computing constraints on my device, I opted to select six different subregions of Egypt to focus on for this analysis, in effort to create two models that are representative of small and large subdivisions when predicting these populations. Egypt consists of two major administrative boundaries, being divided into 27 governorates with over 300 further subdivisions; because of this I decided to run tests on two subsets of the data: one containing five small subregions of Egypt (Ad Daqahliyah, Al Buhayrah, Al Garbiyah, Kafr ash Shaykh, and Al Minufiyah), and one of the largest subregions, Matrouh. To make predictions for populations, we take into account the features of these geographical locations as well as the level of human activity that is taking place in these areas of Egypt. After aggregating all of the filese containing the data we will be working with, I began with 6,109,450 gridcells for the five small subregions and 32,628,528 gridcells for the single large subdivision.
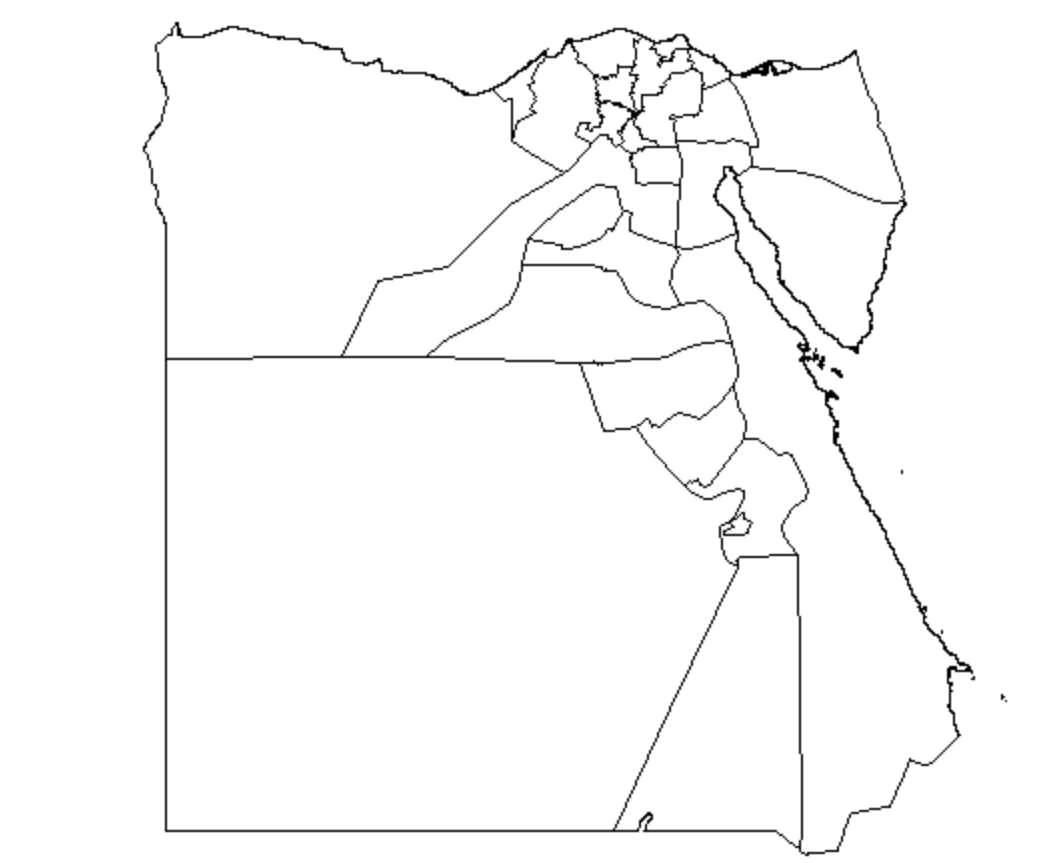
Five smaller sub-regions- Ad Daqahliyah, Al Buhayrah, Al Garbiyah, Kafr ash Shaykh, and Al Minufiyah
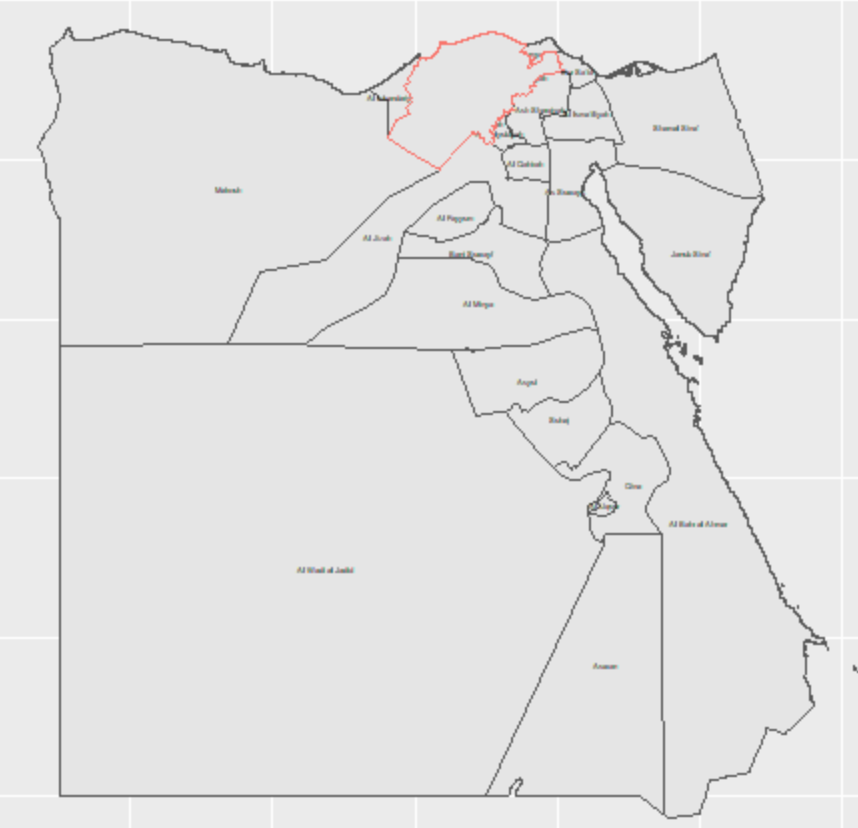
Single large sub-region- Matrouh
Use two machine learning methods predict population values at 100 x 100 meter resolution throughout your selected country
Linear Regression
To begin my analysis, I first used a linear regression model using the sum of various factors such as land use, night time lights, and settlement covariates to predict a population for these subdivisions, before comparing the actual versus predicted populations for these subdivisions in Egypt. This linear regression model utilized a 4/5 proportion for a training/testing split for predicting the population of these subregions on a 100 x 100 meter resolution.
Single Large Subregion- Matrouh
For my single large subregion, my linear regression model predicted a poulation (gridcell count) of 492534.9, and had a real population total of 492481.6, with an absolute difference of 897176. Plots for the population sums and difference in sums are shown below.
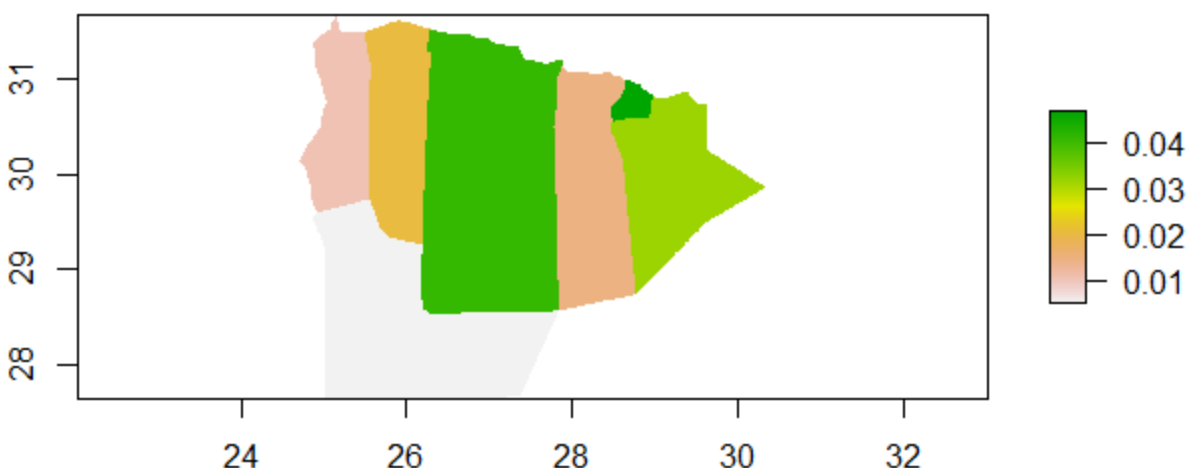
From observing the plot of the difference between the actual and predicted populations shown below, it appears that the model performed fairly well at predicting populations, with only a few places that appear to have been underpredicted.
Difference between actual vs predicted populations
Five smaller subregions- Ad Daqahliyah, Al Buhayrah, Al Garbiyah, Kafr ash Shaykh, and Al Minufiyah
The figure below showcases the plot of the population sums of the five smaller subregions.
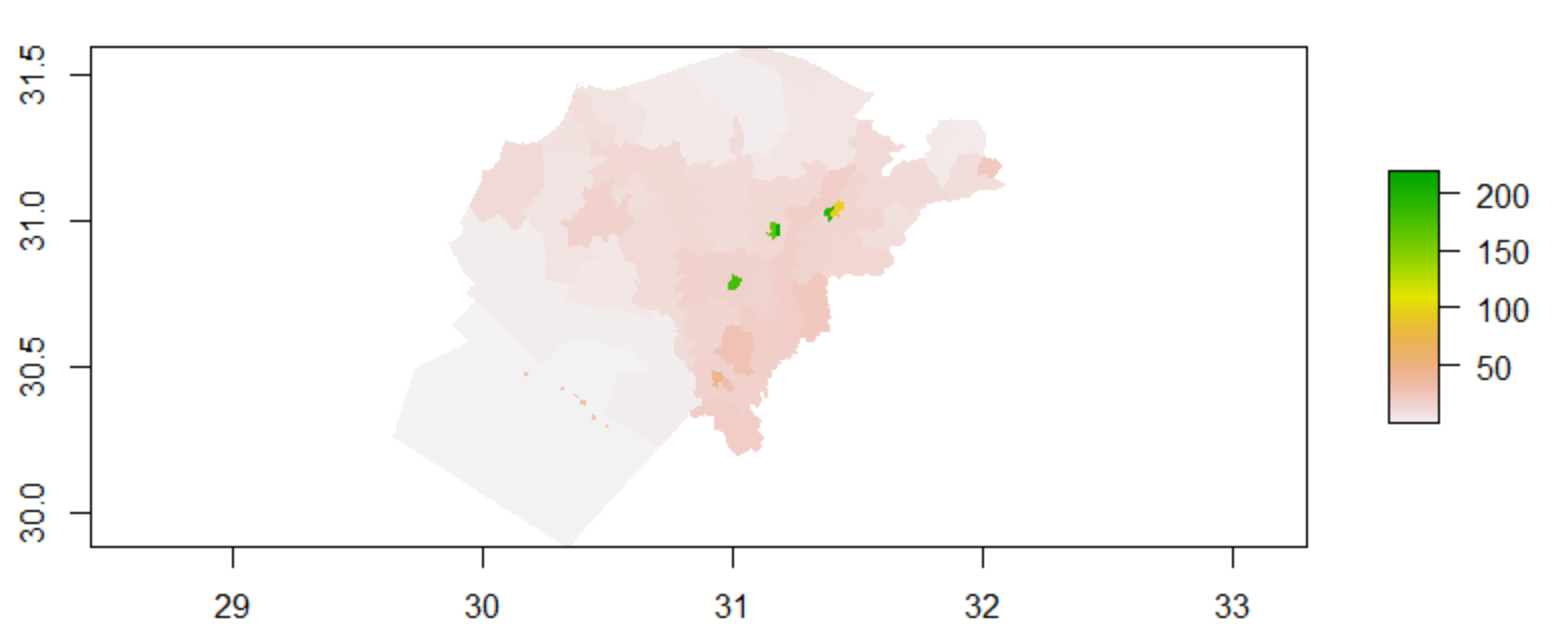
When looking at the predicted populations for the linear regression model, it’s interesting to note a couple of things. First, it should be noted that the model performed moderately well for most of the region, but has localized points in which it grossly underpredicts, surrounded by a small ring in which it overpredicts. Besides the areas of the region that are taken up by lakes and rivers, this is likely due to the presence of cities and travel between the various administrative zones that make up the larger bounds of these cities.
For the five smaller subregions, my linear regression model predicted a population of 25,386,261, and had a real population total of 25,376,857, with an absolute difference of 17,892,728. This demonstrates that the linear regression model underpredicts the overall population of these regions. However, this model performs worse when compared to the previous model ran on the larger subregion.
Difference between actual vs predicted populations
Random Forest
For this random forest regression model, I utilized the same geographic indicators as with the linear regression, utilizing 500 trees that tests four variations of our predictors at each split to predict the population for the various subregions at a 100 x 100 meter resolution.
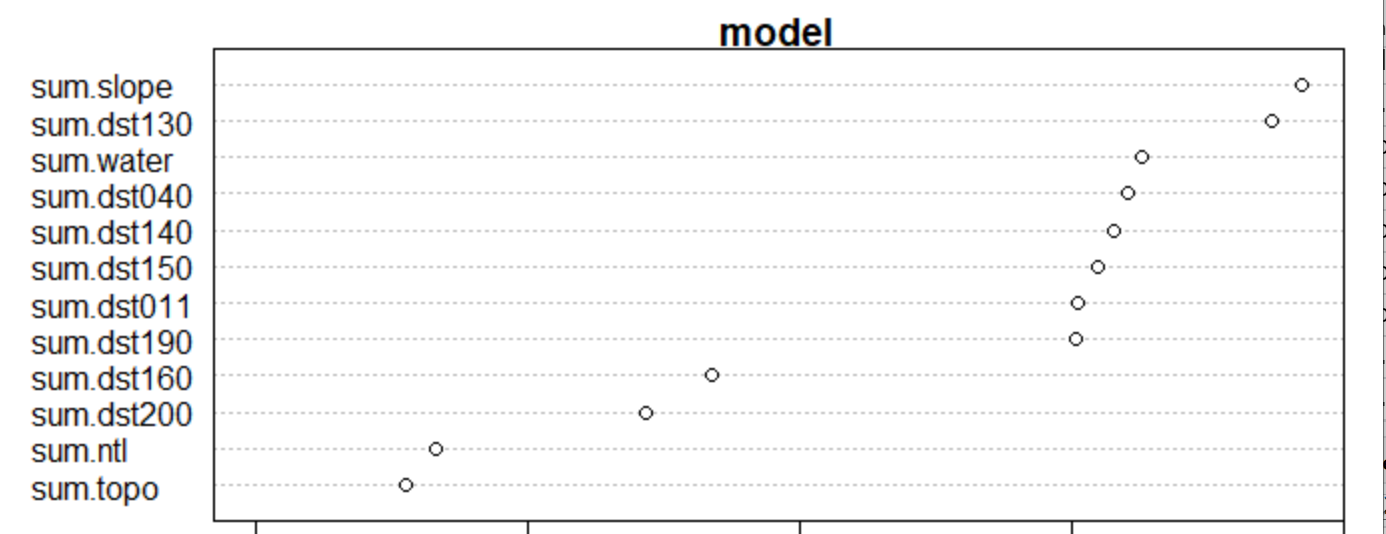
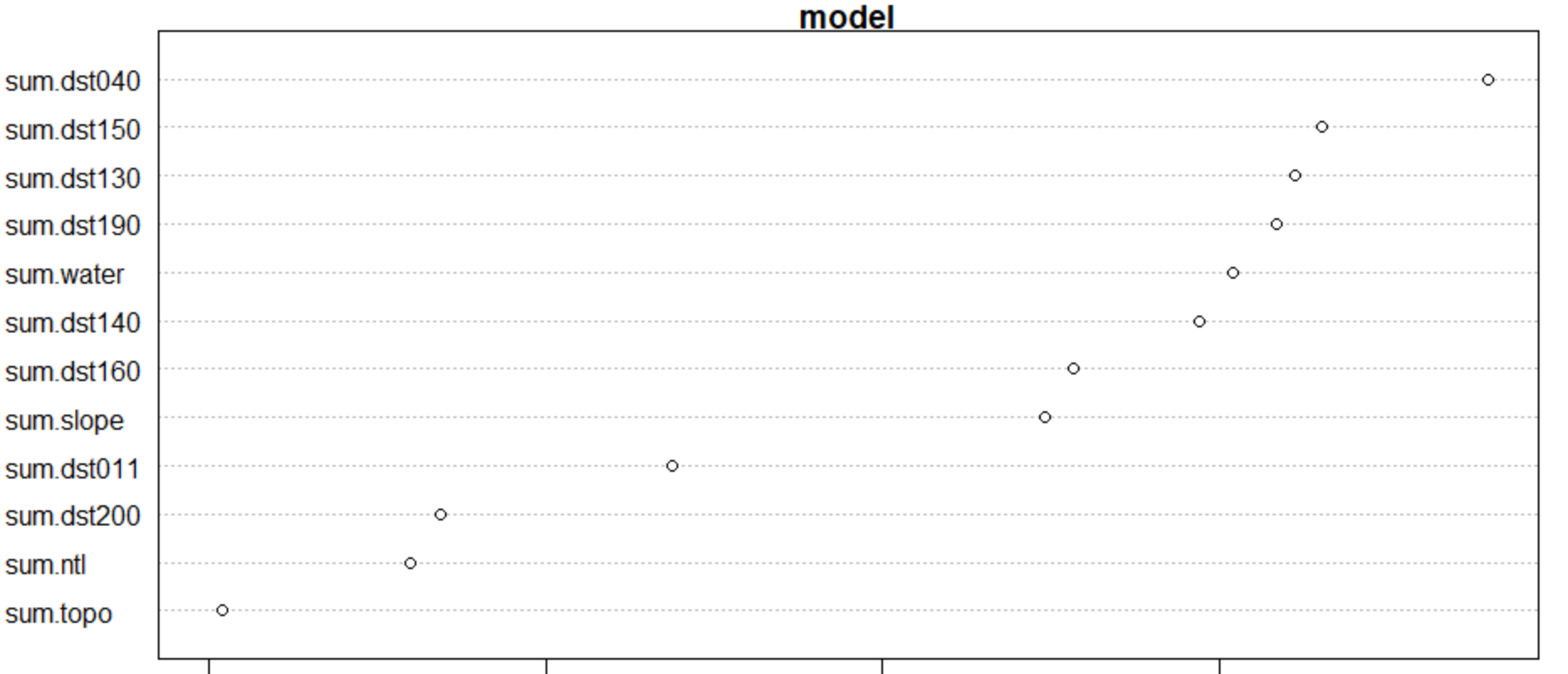
It’s interesting to note the differences in the variable importance plots for each of my two test regions. It appears that for both plots, sum.dst200, sum.ntl, and sum.topo are the least significant predictors when predicting for population. However, sum.dst040, sum.dst150, and sum.dst130 are the top three predictors for the five smaller subregions, while the larger subregion shares sum.dst130 in its top three alongside sum.slope and sum.water. It’s possible that the combination of these factors play a different role when looking at regions of various sizes.
Single large Subregion- Matrouh
VIP Plot
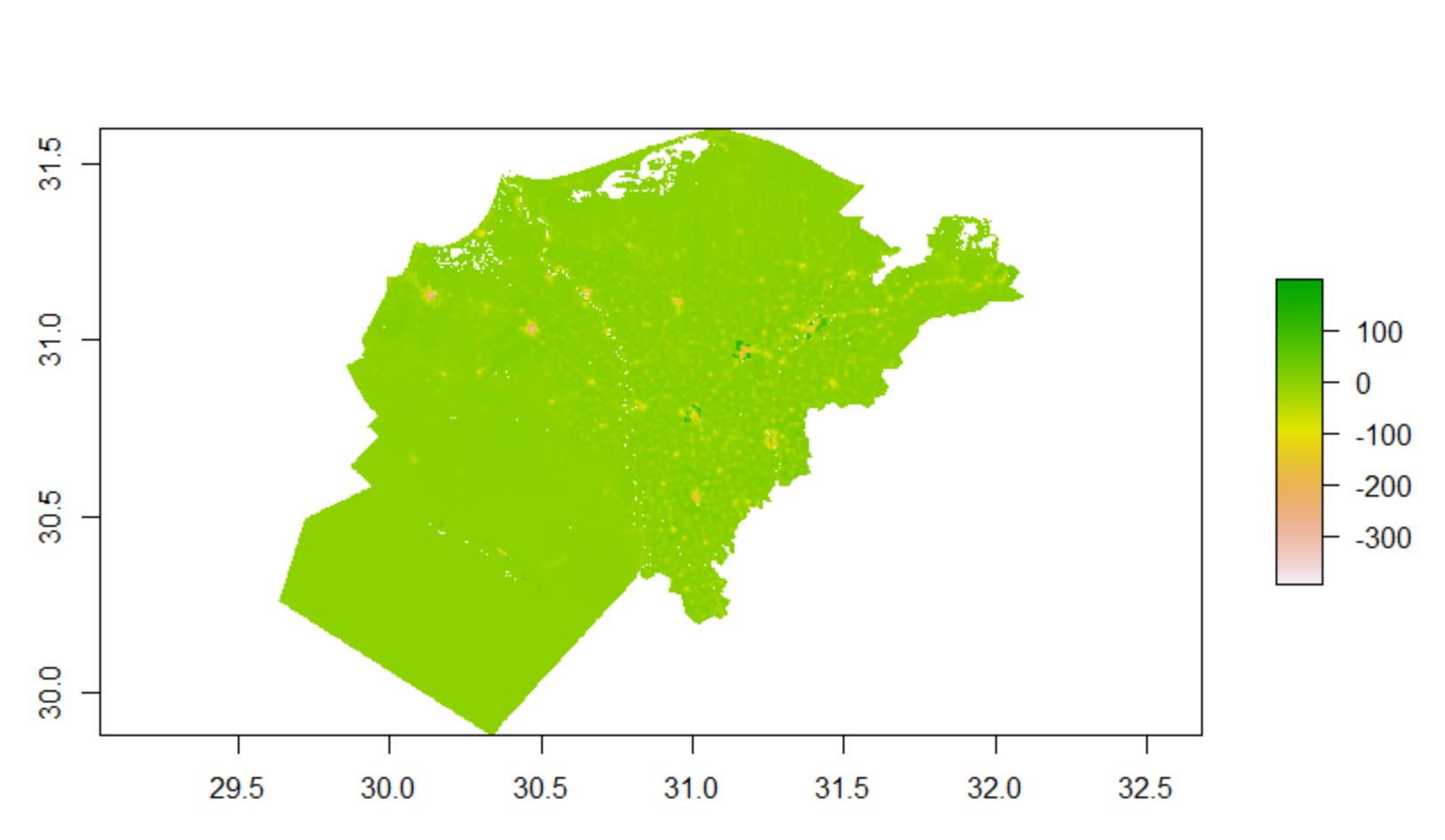
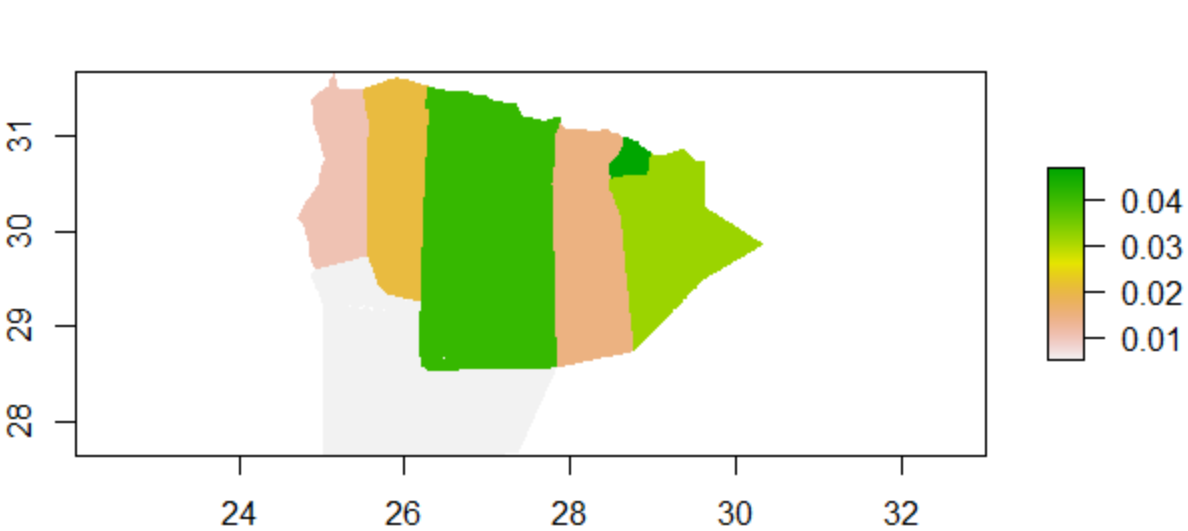
Population Sum
Random Forest Plot
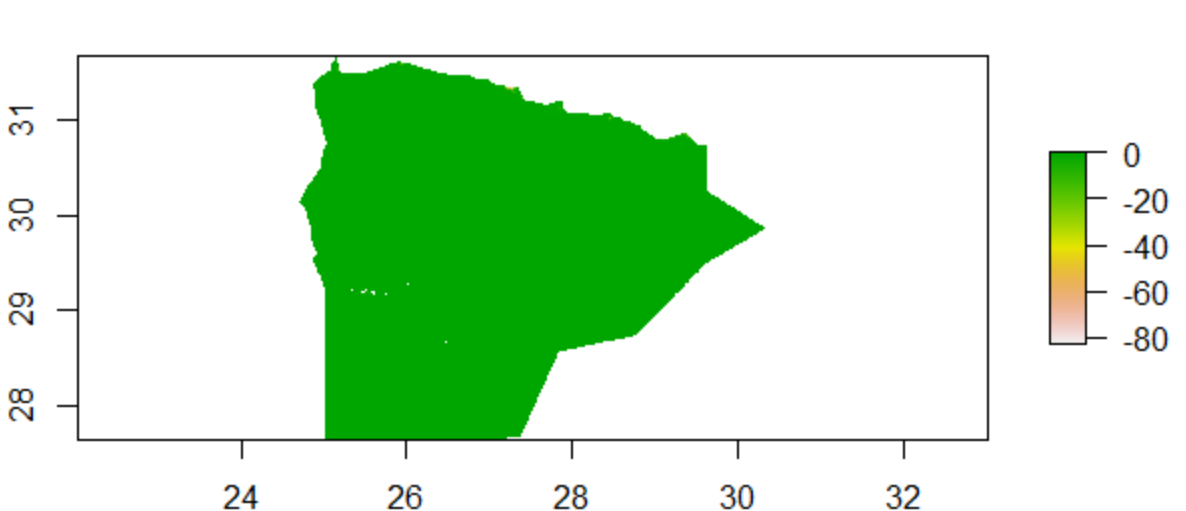
Looking at these plots, it appears that the random forest model performed almost identically to the linear regression, with only a tiny section in the population sum plot that has a noticable change. Arguably, the random forest did not perform any better on this subregion than did the linear regression.
However, this isn’t necessarily supported when analyzing the gridcell counts predicted by this model, with it having a predicted population of 509440.9 and an actual population of 492481.6, and an absolute difference of 897,176. From this, it would appear that the difference in sums is identical to that of the linear regression model, although this model appears to have over-predicted more than the previous model.
Five smaller subregions- Ad Daqahliyah, Al Buhayrah, Al Garbiyah, Kafr ash Shaykh, and Al Minufiyah
VIP
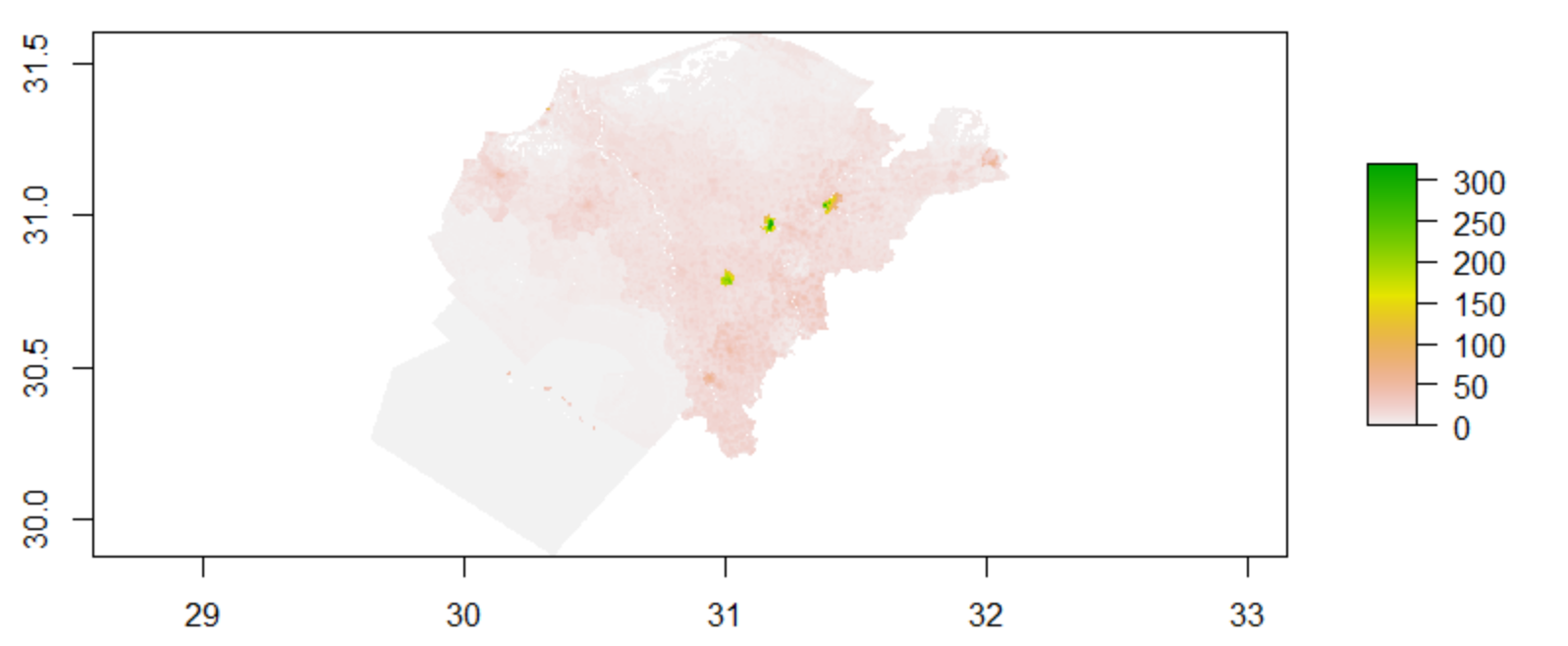
Population Sum
Random Forest
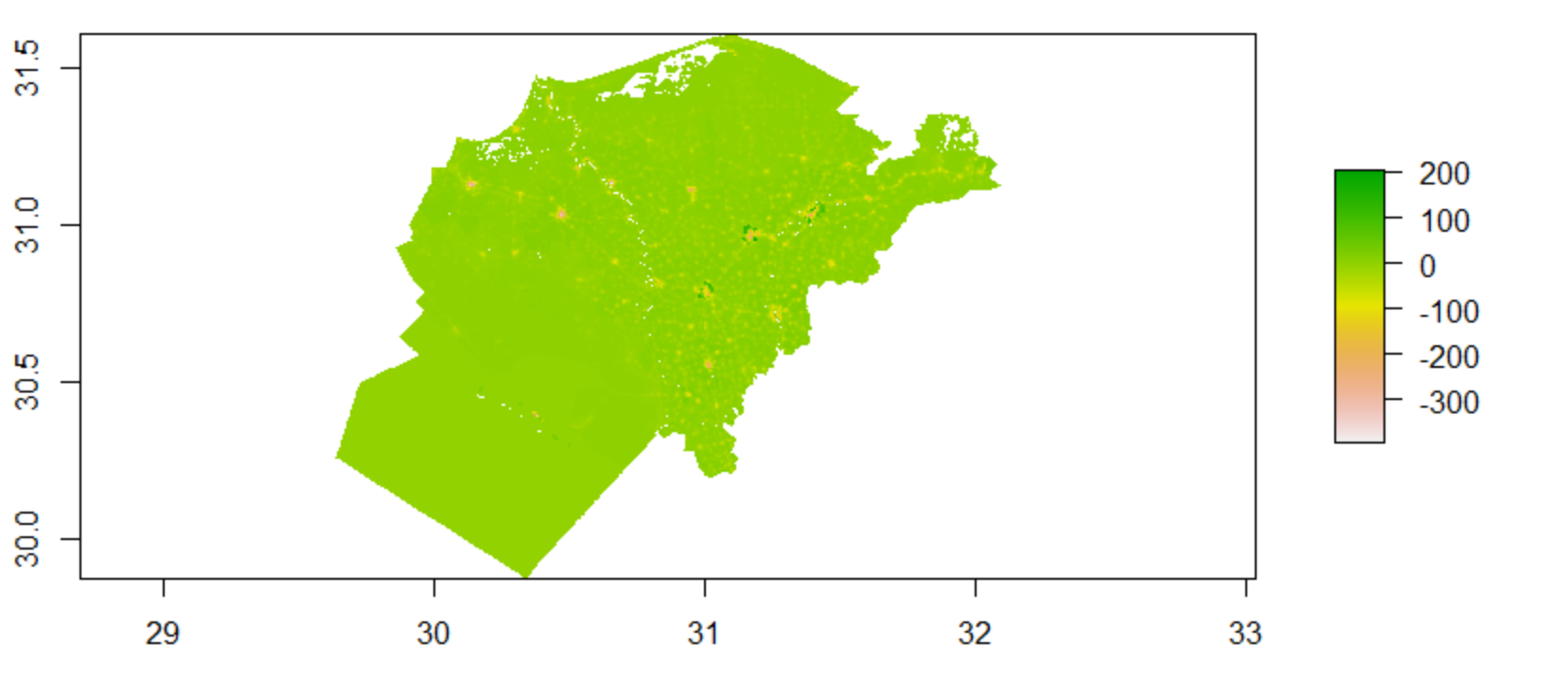
Upon first glance, it would appear that we have a similar case to the plots of the larger subregion, and have an identical performance for both the linear regression and random forest models; however, upon closer inspection, there are some small, but distinct, changes in coloration and intensity that begs the question of which model performed better.
This random forest model predicted a population of 25,386,131, and had an actual population of 25,376,857, with an absolute difference of 17,997,711. From comparing this to the linear regression model, the random forest appears to have performed slightly worse. However, to verify this discovery, I will validate the models using the evaluation metrics of mean squared error and r-squared.
MSE & RSQ
Single Subregion
Random Forest: MSE: 6.112794e+12 R^2: .4492
Linear regression: MSE: 199,599,441,517 R^2: .4301
Five smaller subregions
Random Forest: MSE: 4,416,115,642 R^2:.4432
Linear Regression: MSE: 6.262341e+14 R^2:137.87
Discussion
From observing the results of the validation across all four models, it appears that the random forest model performed slightly better than the linear regression model when taken all together. For the five smaller subregions, the R^2 value was .4432, meaning that 44.3% of the variance in the data can be explained by our present variables. The R^2 value for the random forest on the larger region was slightly higher, with our variables explaining about 44.9% of the variance of the data. I also believe than given the substaintail difference in sizes of the regions chosen, the larger subregion did a better job at predicting populations; however none of the models predict that well, and when taking a look at our predictor variables, this discrepency can begin to be explained.
For example, the night time lights predictor variable may have picked up on locations that contain buildings such as factories that are used for other purposes, but are not necessarily where people live- especially in areas along the borders of the subdivisions that may have increased movement between regions. In additon, both models struggled more when predicting populations within big cities; this is likely due to the fact that in these more urban areas, people are more densely clustered together, and these types of geological factors are not taken into account when building these models.
https://en.wikipedia.org/wiki/Subdivisions_of_Egypt